I have been using static code analyzers for a while now. While these are useful, you need to spend a lot of time analyzing warnings and issues. And the problem is that, after you first run one of the static code analysis tools on a legacy project, you are overwhelmed by the number of issues. Object-Oriented Metrics in Practice, by Michele Lanza and Radu Marinescu, shows us how to use metrics effectively. It shows how to combine metrics in order to spot design flaws. This book also presents some novel visualization techniques. These are a great way to understand and visualize a complex system.

Summary
This book is quite lightweight (in terms of number of pages). In contains seven chapters and three appendices. In this section we’ll provide a brief summary of each chapter.
Introduction
There are two main factors that add to the complexity of a large software system:
- intrinsic complexity of the domain
- incidental complexity caused by team structure, organization and other external factors
Metrics are one way that can help control complexity. The authors don’t present metrics as a Swiss army knife, but as a tool that can help you detect problems. Object Oriented metrics should be correlated with other useful source of information (project history, source control history, historical bug-fix information, etc) in order to detect potential issues. Metrics can’t replace the experience of a software designer, but they can point him in the right direction.
Another advantage of metrics is that they scale. Metrics can describe a system, no matter how big it is. They help spot outliers and reduce the complexity of a software system to something more concrete. I think this is both an advantage and a disadvantage (remember the saying: you get what you measure).
Visualization is another great tool that can help you make sense of a complex system. The approaches presented in this book combine metrics and visualization to asses code bases of any size and complexity.
Facts on Measurements and Visualization
The second chapter defines what a metric is. In order for a metric to be useful, it has to have an explicit goal. That’s why you should view metrics as a source of information, not as numbers. The metrics presented in this book follow the Goal-Question-Metric (GQM) model:
- Goal – what are we trying to achieve?
- Question – what questions do we need to answer to determine if we have achieved the goal?
- Metric – The metrics necessary to answer the question. We usually need many metrics to answer one question.
For a metric to be useful, you need to know what value is too low or too high. The authors employed two ways of identifying threshold values – statistical information and generally accepted semantics.
Visualization complements metrics. Visualization techniques make it easier for a human to extract and analyze information. This book discusses static code visualization. This means that it uses information which can be extracted from the source code, without running the program.
Characterizing the Design
In this chapter, the authors discuss how to characterize a system. This is a tough job, because the basic metrics are too isolated. For a good characterization, you need to correlate multiple metrics and have reference points. The authors propose two techniques for software system characterization: the Overview Pyramid and the Polymetric Views.
The Overview Pyramid
The Overview Pyramid describes and characterizes the structure of a system by looking at three main aspects: size and complexity, coupling and inheritance.
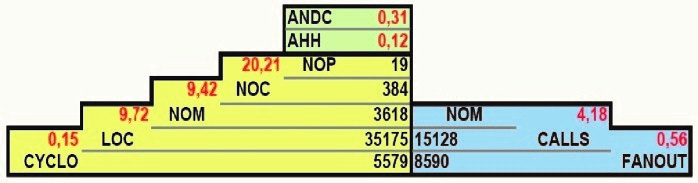
The left part describes the Size and Complexity. It does so by looking at a set of direct metrics and computed proportions. The direct metrics are:
- NOP – Number of Packages
- NOC – Number of Classes
- NOM – Number of Operations
- LOC – Lines of Code
- CYCLO – Cyclomatic Number (the sum of the cyclomatic number for all methods)
The direct metrics have absolute values. Relative values are more useful for comparing systems. This is why the pyramid also introduces computed proportions. These metrics are computed by dividing each direct metric with the one above. Being proportions, these metrics are independent of one another and allow for comparison between projects. The computed proportions are:
- High-level Structuring (NOC/Package)
- Class structuring (NOM/Class)
- Operation structuring (LOC/Operation)
- Intrinsic operation complexity (CYCLO/Code Line)
The right part describes the System Coupling by looking at how intensive and how disperse is coupling in the system.
The direct metrics are:
- CALLS – Number of Operation Calls
- FANOUT – Number of Called Classes
The computed proportions are:
- Coupling intensity (CALLS/Operation)
- Coupling dispersion (FANOUT/Operation Call)
The top part describes the inheritance usages and it contains two metrics:
- ANDC – Average Number of Derived Classes. This characterizes the width of the inheritance tree.
- AHH – Average Hierarchy Height. This is the average of the Height of the Inheritance Tree (HIT) for root classes. A class is a root if it is not derived from another class in the system. This metric characterizes the depth of the inheritance tree.
The computed proportions characterize a system, independent of its size.
The Polymetric Views
A polymetric view is a visualization technique for code elements (nodes) and the relationship between them (edges). A polymetric view can showcase up to seven metrics by relying of the visual attributes of the elements:
- Node size and width
- Node color
- Node position (X & Y coordinates)
- Edge width and color
The authors introduce two polymetric views:
- System Hotspots which helps identify large and small classes
- System Complexity which helps identify the inheritance hierarchies
Evaluating the Design
Metrics are a good tool for revealing hidden assumptions about the structure of a code base. But for metrics to be meaningful, they need to be considered in a context. Without a context, measurability and thresholds do not make sense (when is a class too large?).
A code element has an harmonious design if it is appropriate. It needs to have an appropriate size, appropriate complexity and it needs to comply with the three types of harmony:
- Identity Harmony – How do I define myself?
- Collaboration Harmony – How do I interact with others?
- Classification Harmony – How do I define myself with respect to my ancestors and descendants?
Detection Strategies
Metrics used in isolation can be misleading and provide a limited amount of information. Metrics should be used in combination to provide answers to complex questions about software systems. A Detection Strategy is a composed logical condition, based on a set of metrics for filtering.
Filtering can be Statistical (e.g. the box-plot technique) or Threshold Based. Threshold based filters can use either Absolute Comparators (>, >=, <, <=) or Relative Comparators (highest values or lowest values).
For quantifying more complex design rules, multiple metrics will be composed through AND and OR operators.
The purpose of the detection strategies is to identify suspects for design disharmonies. Design disharmonies are code smells expressed through metrics. The authors present the following process for defining a detection strategy:
- Select informal design rules that describe the design flaw
- Identify Symptoms – break down the informal design rule into symptoms that can be captured by a single metric
- Select Metrics that can quantify each symptom
- Select Filters – for each metric, define a filter for capturing the symptom
- Compose the Detection Strategy
The Class Blueprint
After identifying suspects through Detection Strategies, we need a technique for assessing each suspect. The Class Blueprint is a class visualization technique. A class blueprint separates the methods and attributes of a class into layers, based on time flow and encapsulation:
- Initialization layer – constructors and initialization methods
- External Interface layer – the interface of a class to the outside world. If a method is called from outside and inside the class, then it is placed in the implementation layer.
- Internal Implementation layer – methods that are not visible to the outside world
- Accessor layer – getters and setters
- Attribute layer
A class blueprint maps metric information on the size of a node and semantic information on color. This can help you understand the structure of a class, its call flow and attribute access patterns.
Identity Disharmonies
Identity disharmonies affect methods and classes. These can be identified by looking at an element in isolation. The authors present three rules that contribute to the identity harmony of a code element:
- Proportion rule – “Operations and classes should have a harmonious size, i.e., they should avoid both size extremities”
- Presentation Rule – “Each class should present its identity (i.e., its interface) by a set of services, which have one single responsibility and which provide a unique behavior”
- Implementation Rule – “Data and operations should collaborate harmoniously within the class to which they semantically belong”
Each disharmony is presented in a pattern like format, using the following sections: Description, Applies to, Impact, Detection Strategy, Example, Refactoring.
The authors then present six identity disharomonies:
- God Class – a class that centralizes the intelligence in the system. It is large, complex, has low cohesion and uses data from other classes.
- Feature Envy – methods that access data from other classes, rather than their own data.
- Data Class – classes that expose their data directly and have few methods.
- Brain Method – methods that centralize the intelligence of a class.
- Brain Class – complex classes that centralize a lot of intelligence. A God Class is a Brain Class that also access a lot of data from other classes.
- Significant Duplication – copy-paste clones or copy-paste-adapt mutations.
For recovering from Identity Disharmonies, the authors suggest to start with classes that are “intelligence magnets” and for each of these classes, identify its disharmonious methods. After identifying a culprit, we can use the following process:
- Remove duplication
- Remove temporary fields
- Improve data-behavior locality
- Refactor Brain Method
Collaboration Disharmonies
Collaboration Disharmonies affect the way several entities collaborate to perform a specific functionality. The authors define the collaboration harmony rule – “Collaborations should be only in terms of method invocations and have a limited extent, intensity and dispersion”. A collaboration is disharmonious if it has too many invocations of too many other methods.
Collaboration tackles both incoming and outgoing dependencies. A large number of incoming dependencies makes a class stable (hard to change). A large number of outgoing dependencies makes a class fragile, since it might brake when changing one of its collaborators.
The authors then present three collaboration disharomonies:
- Intensive Coupling – when a method calls many other methods from a few classes.
- Dispersed Coupling – when a method calls methods from a large number of provider classes.
- Shotgun Surgery – when a method is called from many other classes.
Classification Disharmonies
Classification Disharmonies affect hierarchies of classes. Their main cause is using inheritance only as a form of reuse.
The three rules that lead to classification harmony are:
- Proportion Rule – “Classes should be organized in hierarchies having harmonious shapes”
- Presentation Rule – “The identity of an abstraction should be harmonious with respect to its ancestors”
- Implementation Rule – “Harmonious collaborations within a hierarchy are directed only towards ancestors, and serve mainly the refinement of the inherited identity”
The authors then present two classification disharmonies:
- Refused Parent Bequest – when a child class doesn’t use the protected members of its parent.
- Tradition Breaker – when a child class provides a large set of services which are not related to the services provided by its parent.
Appendix
The book also has three appendices. Appendix A contains a catalogue of the metrics used throughout the book. Appendix B is a short overview of iPlasma – an integrated environment for quality analysis of object oriented systems. Appendix C presents CodeCrawler – a software visualization tool which implements the polymetric views.
Biggest Takeaways
How to define a good metric
The authors don’t just present a bunch of metrics. They define a process for identifying metrics, setting thresholds and implementing detection strategies. The Goal-Question-Metric model clearly defines the context in which to use a metric. This makes it easier for the readers to use the same process in order to get answers to their unique questions.
Context is king
Most static code analyzers treat metrics in isolation, so they only show symptoms of bad code. But, as the authors clearly express, one metric can’t tell you if the design is good or bad. Metrics should be evaluated in context and combined in order to detect code smells. The detection strategies do just that.
Detection Strategies
The detection strategies are practical examples of how to identify code smells. Although this book was first published ten years ago, most static code analyzers still don’t have coarse grained detection strategies. I think that most developers today rely on their experience and knowledge to detect design flaws. But tools can and should point us in the right direction. By implementing these detection strategies, we could automate some of this work. And, since the authors also described their train of thought, you can use the same process to define detection strategies that are unique to your project and context.
Conclusion
Object-Oriented Metrics in Practice is a must read if you want to know how to use metrics effectively. It shows how to use metrics to characterize and get an overview of the design of a system. The bulk of the book shows how to evaluate the design and identify design disharmonies by using detection strategies. The authors also present techniques of how to prioritize and recover from these design flaws. The theoretical advice is backed up by lots of practical examples and statistical data extracted from 45 Java projects and 37 C++ projects.
This book also presents some interesting visualization techniques. The Overview Pyramid describes the overall structure of a system. The Polymetric Views contain a lot of information about code elements and their relationships. Class Blueprints help you analyze suspects and quickly assess the structure of a class. It’s a shame I haven’t seen these visualization techniques embedded in more IDEs.
If you’ve ever looked at a bunch of metrics and issues related to your code base and wondered: How should I interpret all this information? Is this good? Is this bad? Where should I start? then this book is for you.
Pingback: Computing the Overview Pyramid metrics with NDepend - Simple Oriented Architecture
Pingback: How to identify common Code Smells using NDepend - Simple Oriented Architecture
Hello, any tips on where to find the book at a good price?
Hi! Unfortunately not – I was lucky enough to find this book in my company’s library.