In a previous blog post we discussed why building the right product is hard and some tips on how to achieve a high perceived integrity. But if you’re building a strategic solution that should support your business for many years, this is not enough. With time, new requirements get added, features change and team members might leave the project. This, together with hard deadlines, means that technical debt starts to incur, and the price of adding new features increases until someone says it will be easier to rebuild the whole thing from scratch. This isn’t a situation you’d like to be in, so that’s why it is important to build the product right.
Building the product right
In their book, Mary and Tom Poppendieck define this dimension of quality as the conceptual integrity of a product. Conceptual (internal) integrity means that the system’s central concepts work together as a smooth, cohesive whole.
How can you maintain the conceptual integrity of a product during its lifetime? You rely on communication, short feedback loops, transparency and empowered teams. These are the same principles that can lead to a high perceived integrity. The only difference is that you apply them at an architectural and code level.
Architecture and Design Quality
In Software Architecture for Developers, Simon Brown says that architecture is about structure and vision. Architecture is about structure, because it breaks a solution in high level components and defines the interaction model between these components. It’s about vision because architecture requires a shared understanding of how to solve the problem. Both structure and vision need to be communicated to the entire team. Also, they can be improved with feedback from the team and the system itself.
Top-level Architecture
Again, Domain-Driven Design helps us communicate the structure of our solution. If you’re working in a sufficiently complex environment, then DDD might be a good fit. Beware though, do not over complicate the solution by applying DDD to trivial domains.
The bounded context pattern is a good way for decomposing your domain. A bounded context helps protect the integrity of a model and defines its interaction with other models. This means it might be a good option for structuring your domain. If you define your contexts and set clear rules on the communication patterns between them, you’re in a good place. Of course, bounded contexts might change, split or merge over the lifetime of a project. There’s a higher chance of this happening in the first months of working on a new product. Over time, the boundaries between contexts should become more stable. This is because the human factor is at the core of defining the bounded contexts – and this is pretty stable. Think of departments in an enterprise – how often do they change?
If you’ve read about Service Oriented Architecture, you may notice a lot of similarities between services and bounded contexts. They share many of the same characteristics, like autonomy and being focused on business capabilities. Because it clearly defines the structure and helps communicate the vision, SOA might be a good option for the top-level architecture. You could start with one service per bounded context. As you learn more about the domain, you might decide to further split a bounded context into multiple services.
Design and the Big Ball of Mud
Every team makes architectural and design decision. You might have a dedicated architect in the team, or some team member undertaking the architecture role. There might be some architectural decisions already made and hard to change. But the team makes design decisions every day. Every single line of code is based on small decisions that might seem insignificant. But when you add them up, these decisions shape your code base. Case in point – almost nobody started a project wanting to build a big ball of mud. I bet that most of the projects that ended up that way were designed differently and had a set rules on how the components should interact. Most of them had a target architecture even though the end result doesn’t follow it.
I think a reason why this happens is because the team that does the coding isn’t involved enough in the design process. These are the people who implement the design. They will be among the first affected by a wrong design decision. These are the people who can tell you if the design is right or not. They should take part in the design process. This is a reason why agile has better results: there is almost no difference between designing and planning the work vs. doing the work. Of course, this can have downsides – there have been many projects that failed because there was no design at all. Agile doesn’t mean we can throw away the design, but that we need to design just enough, just in time!
Design Process
There are many ways of how to achieve this. Depending on the team size, designing should be done on multiple levels. In a multi team setup, a viable option would be to split it into two different activities:
- Representatives from all the teams should review the top level architecture. This includes specifying the interaction model between services and defining the published interfaces.
- Designing features within a service should be a team activity. I always get valuable insights when I’m with my team in front of a whiteboard.
There should be clear feedback loops between these different levels. This will help maintain the consistency of the code base and reveal improvement points, as well as communicate the vision of the product.
Communicating Design
It’s also important how you communicate design decisions. These should not be treated as set it stone. If while implementing a feature, the team discovers some issues with the agreed upon design, they should be empowered to challenge it and even change it. This doesn’t mean the team should overrule all design decisions. There might be some constraints or trade offs that the team isn’t aware of. If an architect was involved in making the design, he should be consulted/informed when it is changed.
If designing is a whole team activity, then the team will understand the reasoning behind design decisions. They will know the constraints and trade offs and they will feel empowered to give feedback.
Code Quality
Coding Guidelines
In many situations, coding style is a matter of taste. Members of the team might have different views on style. But consistency should trump personal taste. Every project should have a set of coding guidelines and every team member should follow it. Since many times this is tedious work, you should automate the checks. In the .Net world, we use StyleCop to enforce the style and consistency rules. You can integrate your StyleCop ruleset into your ReSharper clean up profile. This way rules are checked and applied automatically, so you can focus on more important things.
You should also use a static code analysis tool that can warn you of design issues. I use FxCop/CodeAnalysis which ensures that we follow the Microsoft .NET Framework Design Guidelines. It also picks up some performance and security improvements.
All these tools should be integrated into your deployment pipeline.We use SonarQube for aggregating quality information and surfacing it into some developer friendly dashboards. SonarQube also has its own rules and metrics, like code duplication and technical debt. Be warned though: don’t treat Sonar issues in isolation. You should investigate each one in its context and correlate it with neighbor issues. It would be useful to have tools which signal code smells, not issues in isolation. Unfortunately, I don’t know one in the .Net world. If you do, please leave a comment.
Code Inspection
But you can’t automate all checks. A tool can’t tell you if you’ve implemented the wrong algorithm or detect all the code smells. Someone else should inspect your code.
Reports show that code review is the number one way to improve code quality. And obviously, code reviews help you detect possible bugs or issues. But I don’t think this is their greatest benefit. Code reviews encourages knowledge sharing within the team, so you don’t have polls of knowledge. Code reviews encourage learning. From my experience, pair programming and code reviews are one of the most efficient ways for a team to learn and grow. You should get your code reviewed and you should review other peoples code. A LOT.
Successful Code Reviews
10 lines of code = 10 issues.
500 lines of code = "looks fine."
Code reviews.
— I Am Devloper (@iamdevloper) November 5, 2013
For a code review to be successful, you should do it in small batches. Reviewing tens of files takes hours and you’ll likely miss many issues (if it’s not taking hours, you’re probably rushing). Since it requires a deep level of concentration and focus, a code review should not take more than one hour. In most of the cases I review code before check in. If you’re using git, a pull request is a good way to review code before you merge it into trunk. If you follow the discipline of checking in at least once a day (but preferably more often), you should be all set. As a side note, I also favor developing on mainline. This ensures that work is integrated often and integration days or code freezes are not needed.
You should also consider shared code review session if you’re working in a multi-team project. These sessions focus more on knowledge share and less on detecting quality issues. This helps teams align and gain knowledge on the entire code base. It also improves consistency and helps avoid oddball solutions. Sometimes, these sessions reveal design issues. It is important to add these improvements to your backlog and figure out how and when to work on them. I always favor the boy scout rule over dedicated refactoring stories, but sometimes I can’t see a better way of paying the debt. You should always keep an eye out for technical debt, and SonarQube metrics are not enough.
Testing Strategy
To achieve a high conceptual integrity you need to clearly define the testing strategy. This should provide a guideline of when to test, what to test, and how to test. There are way too many agile projects that require a huge effort of manual regression tests before each release. In order keep the cost of adding a feature low, you need to have a safety net to protect you against regressions.
Although the testing strategy depends on the type of product that you are building, there are some overarching themes. One of the most simple to understand but harder to follow concepts is the Test Pyramid, pictured below:
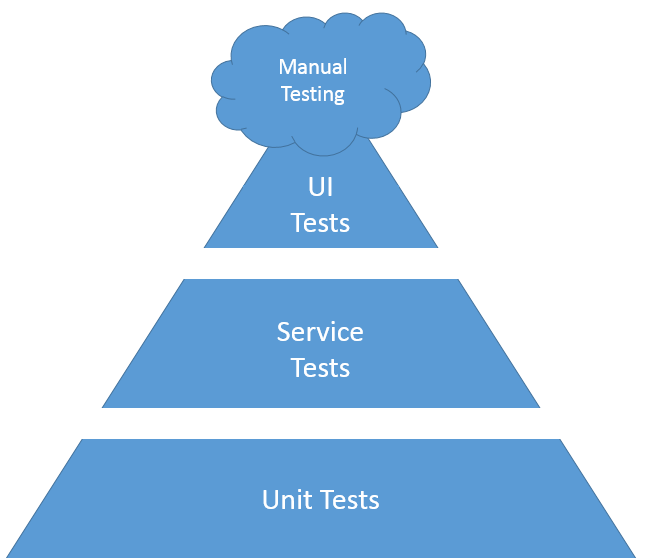
You should focus most of your testing effort on the low level, fast and focused unit tests and less on end-to-end tests. The more broad the tests are, the fewer you should have. This is because as you go up the pyramid, tests become more brittle, harder to maintain and more expensive to run.
Also, the Test Pyramid relies on the fact that you’ll automate as much as you can. There are some tests that are too expensive to automate and don’t provide a high return on investment. One example would be usability testing. Other tests cannot be automated – for example exploratory testing, which relies on the creativity of testers. So there will always be some manual testing. But to be agile and be able to adapt to ever-changing requirements, you must know as fast as possible if you have introduced a regression. This means that manual testing should be reduced to a minimum and regression tests should be automated and integrated into your deployment pipeline.
Conclusion
Maintaining a high conceptual integrity is hard. In this blog post we’ve just scratched the surface on some of the things you can do in order to ensure you’re building the product right. Luckily, there are many books that touch on this topic in one way or another. Here are some books that I highly recommend:
- Lean Software Development: An Agile Toolkit by Mary Poppendieck and Tom Poppendieck
- Software Architecture for Developers by Simon Brown
- Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans
- Patterns, Principles, and Practices of Domain-Driven Design by Scott Millett
If you’d like to find out more on any of these topics or share your experience, please leave a comment below.